





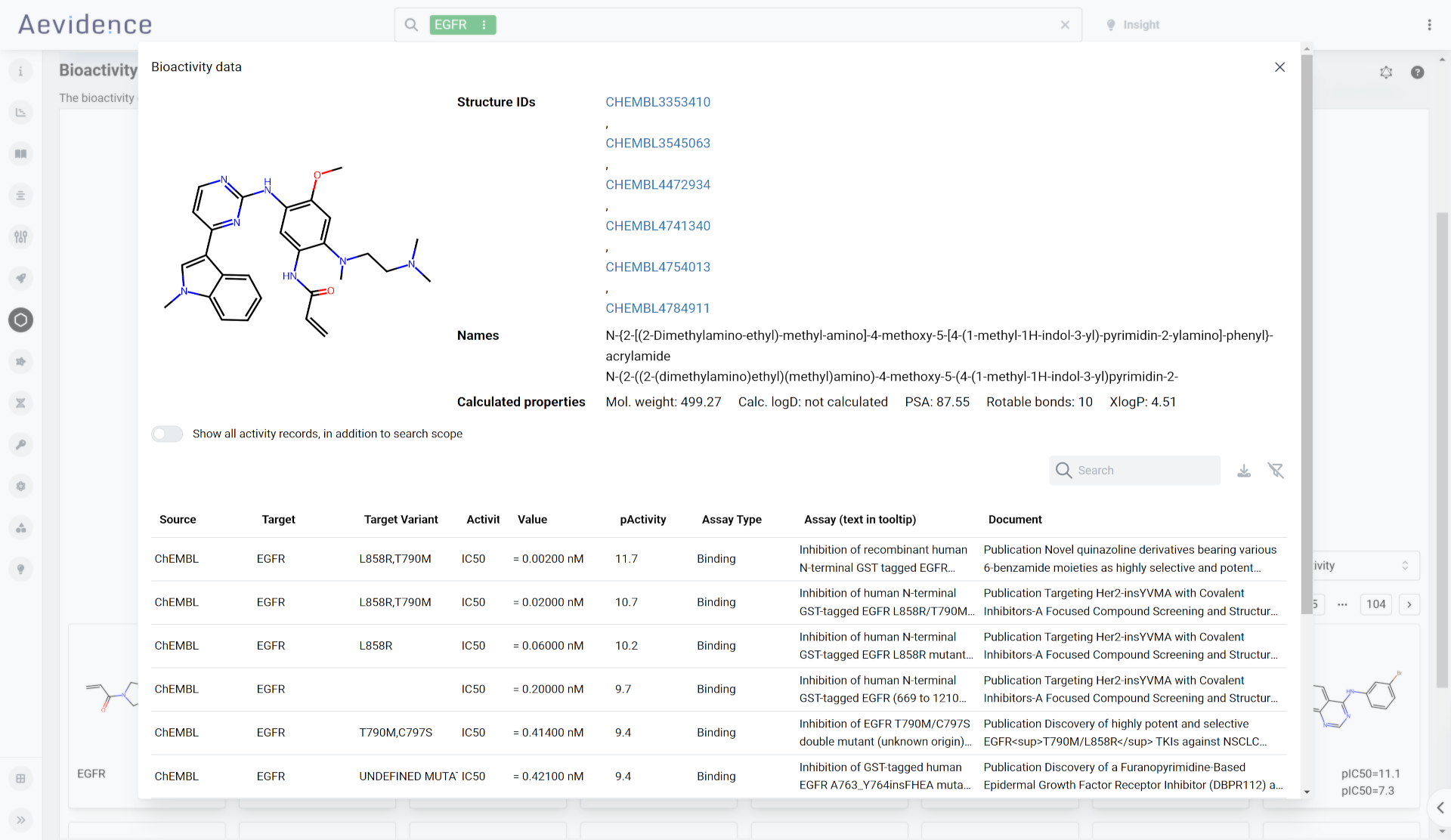
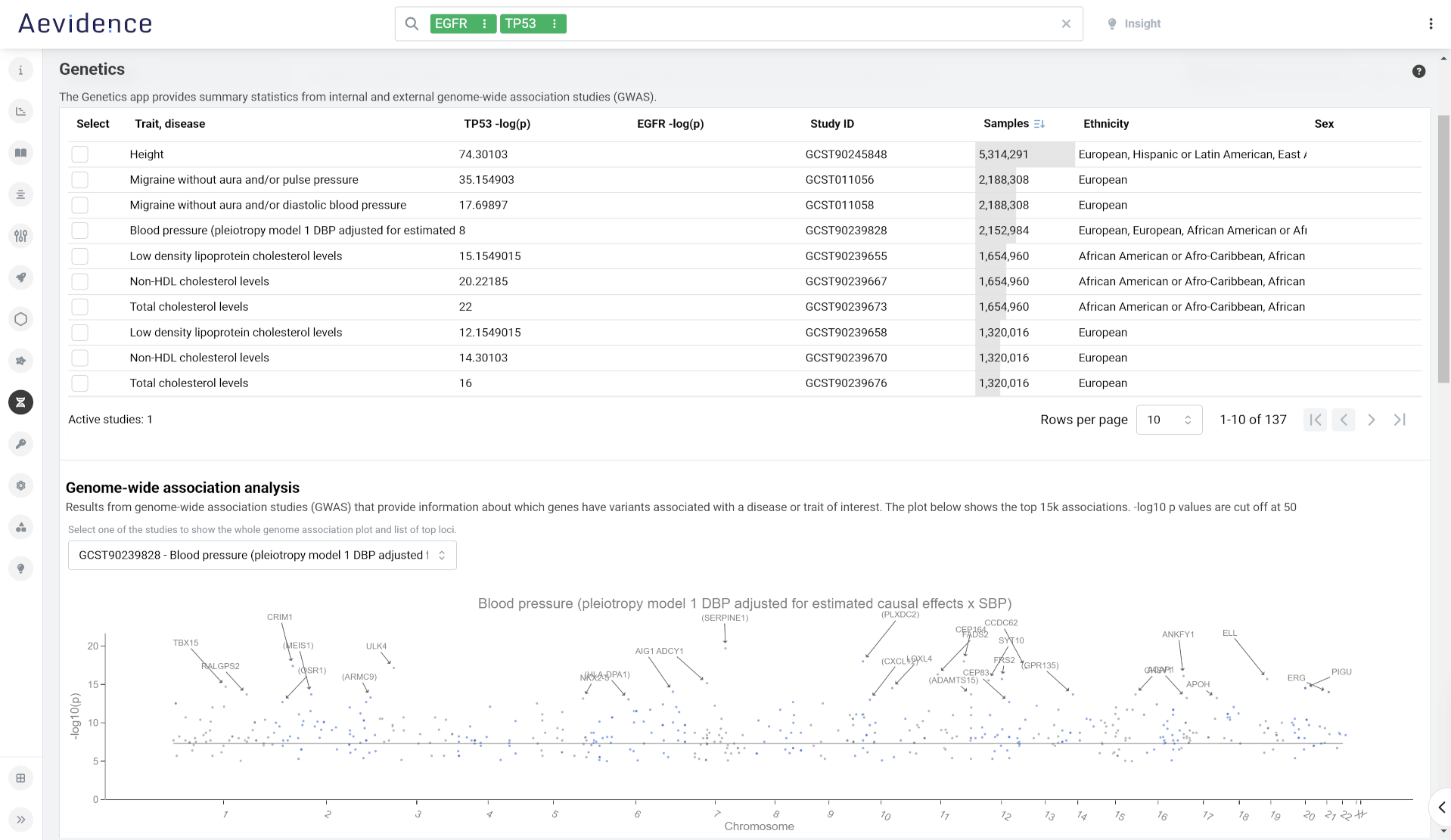
Get summary statistics from internal and publically available data from genome-wide association (GWAS) studies and PheWAS phenome-wide association (PheWAS) studies, with links to publications in PubMed. Select a study to review GWAS study information about genes with variants associated with a specific disease or trait, and drill down to see a regional association plot of any trait associations within a given genomic range.
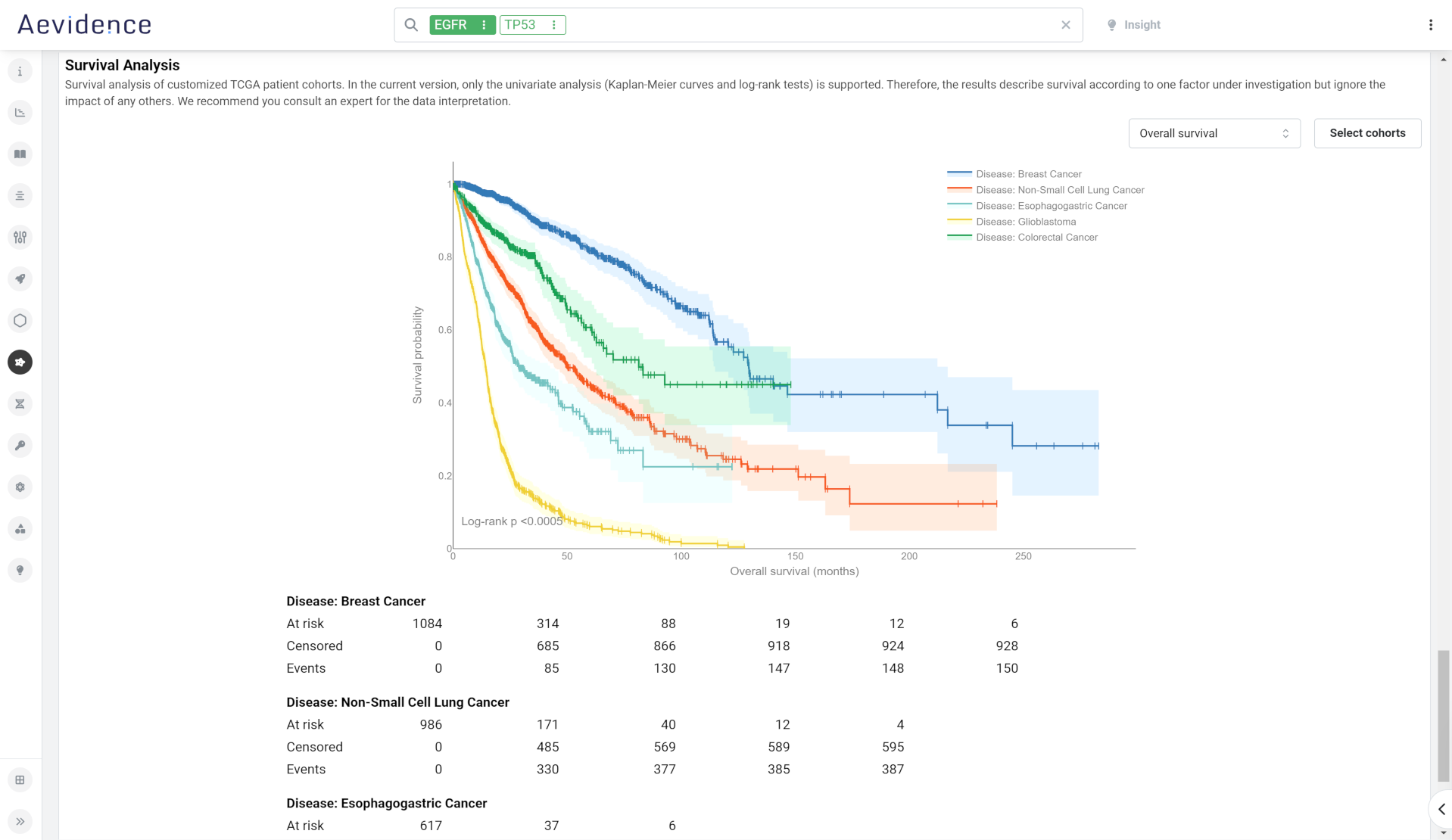
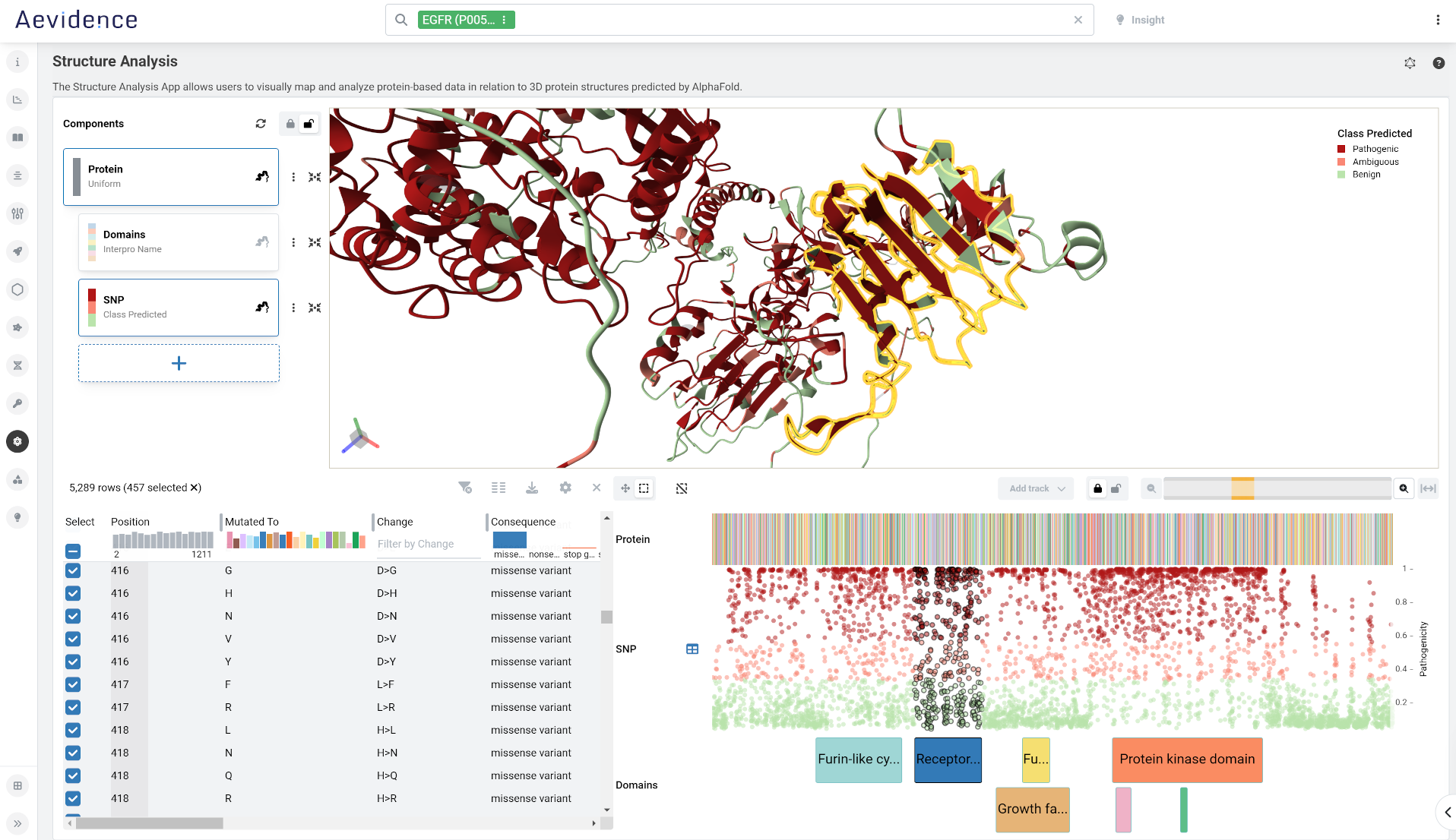
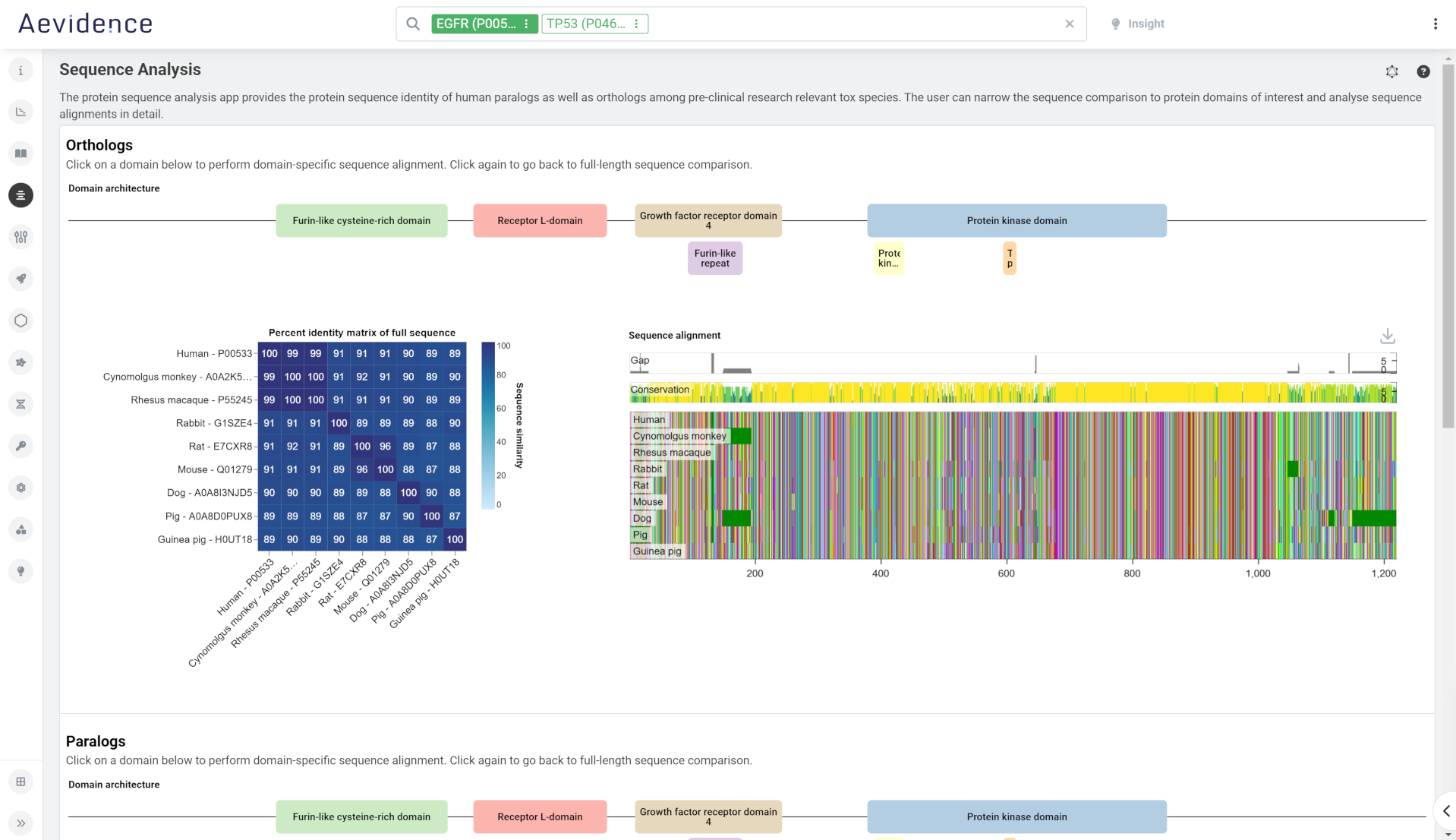
Access a visual overview of genomics alterations documented in The Cancer Genome Atlas (TCGA) . For selected genes, this portal presents genomic alteration prevalence by cancer type, gene expression distribution in tumor and normal samples, missense mutation hotspots, DepMap gene effect scores for CRISPR knock-outs across different cell lineages and survival analyses for selected patient cohorts.
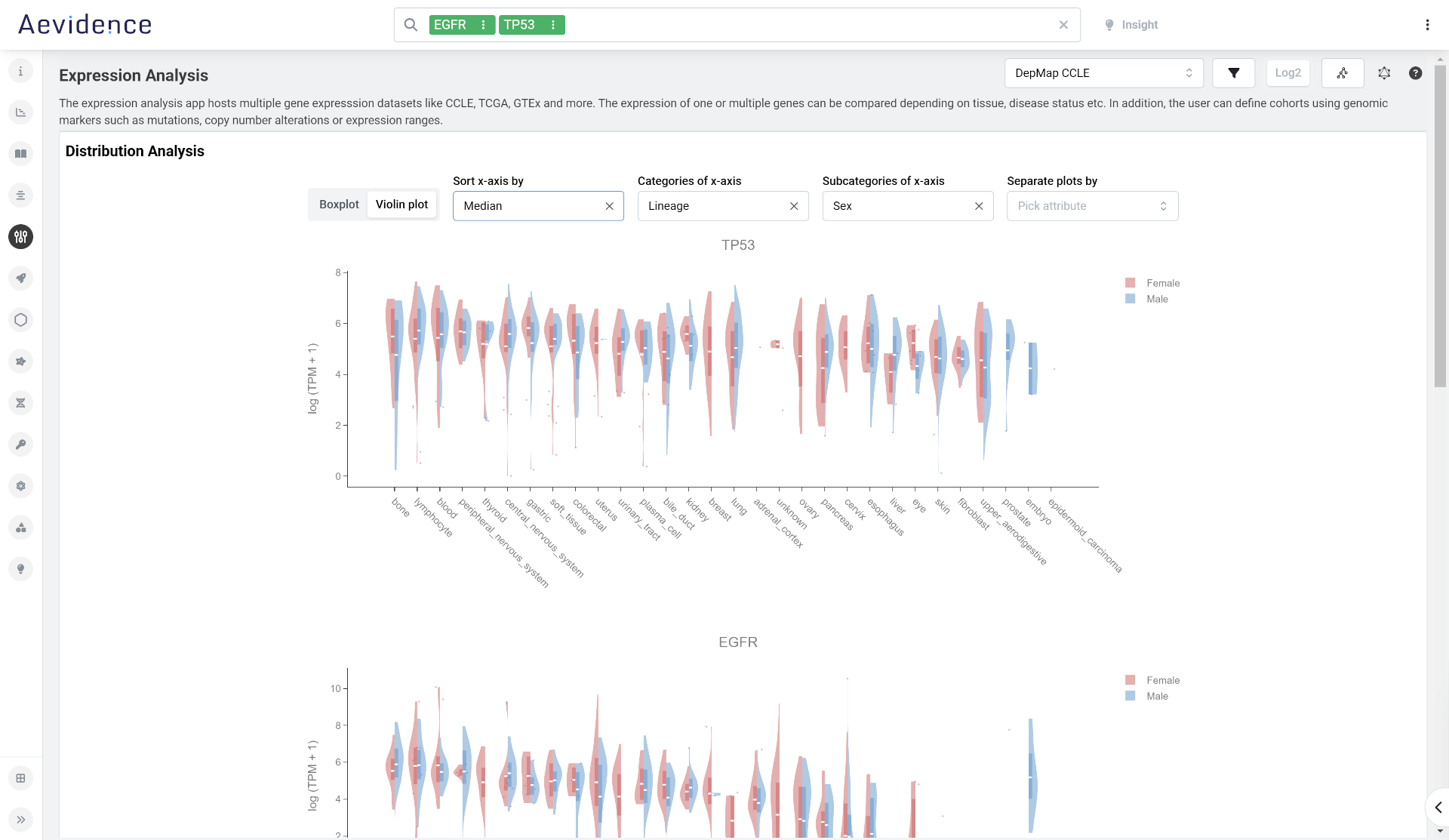
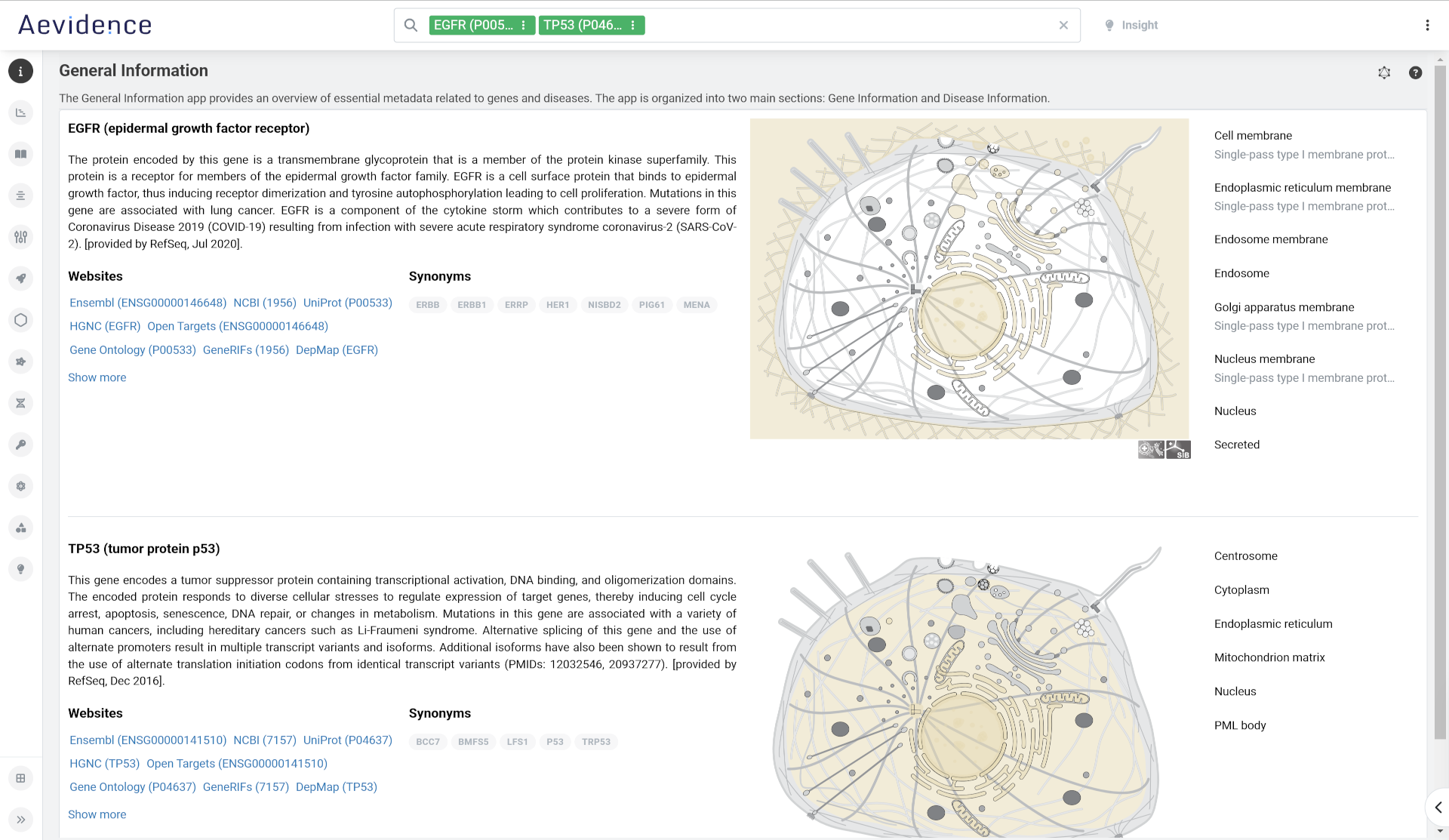
Compare expression of one or multiple genes using integrated data from the Genotype-Tissue Expression (GTEx) portal, The Cancer Genome Atlas (TCGA), and Cancer Cell Line Encyclopedia (CCLE). Here, you can visualize expression data in the context of a specific tissue type, disease status, or other factors. You can also define cohorts using genomic markers (e.g., mutations, copy number alterations, expression ranges, etc.).
Work with us to create new portals tailored to fit your requirements and discovery data landscape.
