visynKB is a Unified Biological Knowledge Platform
visynKnowledgebase (visynKB) is a foundational discovery knowledge base and ETL pipeline that integrates public data from a wide range of biological and drug data sources information available with published data from landmark disease studies.
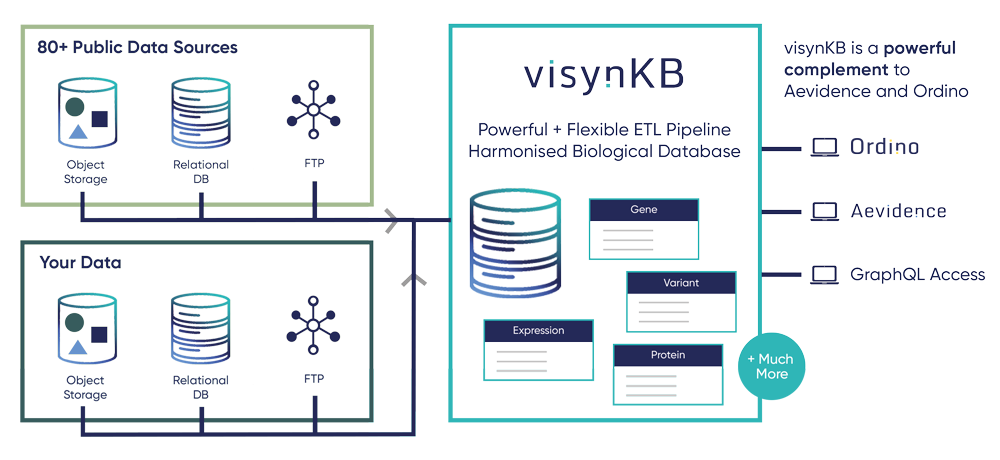
visynKB is a unified biological knowledge platform that interconnects 80+ carefully curated drug discovery and genomics datasets—from ChEMBL and DrugCentral to TCGA, OpenTargets, and GWAS Catalog—so researchers can answer complex questions through a single GraphQL API, not spreadsheets and database hopping.
Accelerate target prioritization, compound profiling, and disease translation without the integration headache.
Core Knowledge Base: Comprises data from more than 80 bioinformatics and disease-specific resources.
Powerful ETL: Enhance visynKB data with your in-house experimental data, using our easy to use visynPlugin system (with support from our bioinformatics experts).
Tailored Experience: Our team of data visualization and bioinformatics experts is happy to work with you to create a custom visynKnowledgebase that perfectly supports your research focus.
Take a closer look at the vast array of biological intelligence included in the current version of the visyn Knowledgebase, which includes data from the Universal Protein knowledgebase (UniProt), Genotype-Tissue Expression Portal (GTEx), ChEMBL, and Reactome as well as cancer research-specific resources, such as the cBioPortal for Cancer Genomics, Cancer Dependency Map Project (DepMap), and The Cancer Genome Atlas (TCGA).
| Title | Category | Description | Link |
|---|---|---|---|
| AACR Project GENIE | Cancer Genomics | GENIE(Genomics Evidence Neoplasia Information Exchange) is a large-scale, international data-sharing initiative focused on cancer genomics. It was launched by the American Association for Cancer Research (AACR) with the goal of accelerating precision medicine for cancer. | Link |
| depmap | Cancer Genomics | DepMap (The Cancer Dependency Map) is a research initiative and database that identifies essential genes for cancer cell survival. By targeting these genes in various cancer cell lines. To represent the diversity of human cancer, DepMap builds on the original Cancer Cell Line Encyclopedia (CCLE) project and more than 2000 cell line models have been collected. | Link |
| cBioPortal | Cancer Genomics | cBioPortal is a web-based tool for exploring cancer genomics data, it provides access to large-scale cancer datasets, allowing researchers and clinicians to explore genetic mutations, alterations, and clinical outcomes across different cancer types. | Link |
| TCGA | Cancer Genomics | TCGA (The Cancer Genome Atlas) is a comprehensive project that provides detailed genomic, epigenomic, transcriptomic, and clinical data on various types of cancer. | Link |
| Systematic analysis of protein turnover in primary cells (Paper) | Chemical Biology | data from the Systematic analysis of protein turnover in primary cells paper | Link |
| miRWalk | Chemical Biology | miRWalk is a comprehensive database that provides information on microRNA (miRNA) target predictions. It offers data on the potential binding sites of miRNAs on genes across the entire genome. miRWalk integrates both predicted and experimentally validated miRNA-target interactions, covering a wide range of species. | Link |
| NA (Paper) | Chemical Biology | data from paper: 'Reimagining high-throughput profiling of reactive cysteines for cell-based screening of large electrophile libraries' | Link |
| FDA - UNII | Clinical | FDA - UNII (Unique Ingredient Identifier) is a system developed by the U.S. Food and Drug Administration (FDA) to assign unique, non-proprietary identifiers to substances used in pharmaceuticals, biologics, food, and cosmetics. | Link |
| Protac-DB | Drug/Compound | Protac-DB is a specialized database focused on PROTACs (PROteolysis-TArgeting Chimeras). PROTACs are a novel class of therapeutic agents designed to target and degrade specific proteins within cells by harnessing the cell's own ubiquitin-proteasome system. Protac-DB provides comprehensive information on PROTACs, including their structures, target proteins, mechanisms of action, and related research. | Link |
| ChEMBL | Drug/Compound | ChEMBL is a manually curated database of bioactive molecules with drug-like properties. It brings together chemical, bioactivity and genomic data to aid the translation of genomic information into effective new drugs. | Link |
| ChEBI | Drug/Compound | ChEBI (Chemical Entities of Biological Interest) is a dictionary of small molecular entities used to standardize chemical nomenclature by offering a consistent way to describe and reference chemical entities. | Link |
| Drugbank | Drug/Compound | DrugBank is a comprehensive database that provides detailed information on drugs and drug targets | Link |
| FDA - Adverse Event Reporting System | Drug/Compound | The FDA Adverse Event Reporting System (FAERS) is a database that contains information on adverse event and medication error reports submitted to FDA, designed to support the FDA's post-marketing safety surveillance program for drug and therapeutic biologic products. | Link |
| UbiNet | Drug/Compound | UbiNet 2.0 (Database of E3-Substrate Interactions) is a knowledge repository that provides updated, validated, and abundant E3-substrate interactions, detailed classification of human E3 ligases, and visualization tools to investigate ubiquitination network. | Link |
| Drugcentral | Drug/Compound | DrugCentral is an online drug information resource that provides information on active ingredients chemical entities, pharmaceutical products, drug mode of action, indications, pharmacologic action. | Link |
| The Human Protein Atlas | Expression | The Human Protein Atlas is a comprehensive resource that provides detailed information on the expression, localization, and function of proteins in human tissues and cells. | Link |
| GTExPortal | Expression | The Genotype Tissue Expression (GTEx) is a comprehensive resource of WGS, RNA-Seq and QTL data from 54 non-diseased tissue sites across nearly 1000 individuals to study human gene expression and regulation, and its relationship to genetic variation across multiple diverse tissues and individuals. | Link |
| Ensembl – Gene | Gene | Ensembl is a comprehensive genome database that provides detailed information about genes and their associated genomic features across a wide range of species, including humans. | Link |
| Borealis | Gene | Borealis, the Canadian Dataverse Repository is a platform that provides access to research data across various disciplines. Hosted by Scholars Portal, we use Borealis as a source for conservation scores. | Link |
| Gencode | Gene | Gencode is a resource for comprehensive and accurate annotations of human and mouse genomes. | Link |
| NCBI - Gene | Gene | NCBI gene integrates information from a wide range of species. A record may include nomenclature, Reference Sequences (RefSeqs), maps, pathways, variations, phenotypes, and links to genome-, phenotype-, and locus-specific resources worldwide. | Link |
| Ensembl – Gene | Gene | Ensembl is a comprehensive genome database that provides detailed information about genes and their associated genomic features across a wide range of species, including humans. | Link |
| NCBI - Orthologs | Gene | NCBI's Eukaryotic Genome Annotation pipeline identifies ortholog gene groups for the NCBI Gene dataset using a combination of protein sequence similarity and local synteny information. | Link |
| HomoloGene | Gene | An automated system of the NCBI for constructing putative homology groups from the complete gene sets of a wide range of eukaryotic species | Link |
| EBI – HGNC | Gene | EBI – HGNC (HUGO Gene Nomenclature Committee) is an organization that provides a standardized and unique naming system for human genes. | Link |
| Pig RNA atlas | Gene | The Pig RNA Atlas presents the genome-wide expression of all 22342 protein-coding genes in 98 pig tissues. | Link |
| Biomart | Gene | BioMart is a data management system provide an easy-to-use web-based tool that allows researchers to query, filter, and retrieve biological data from multiple databases in a unified and efficient manner. we use BioMart as a source for gene and protein identifiers mapping. | Link |
| MyGene | Gene | MyGene is a web-based resource that provides a simple-to-use interface for accessing gene annotation data. | Link |
| GeneRIF | Gene | GeneRIF (Gene Reference Into Function) is a database that provides concise summaries of the functions of genes, based on information from scientific publications. | Link |
| EBI – GWAS Catalog | Gene | The EBI – GWAS Catalog is a public database that compiles results from genome-wide association studies (GWAS). These studies investigate the associations between genetic variants and traits or diseases. | Link |
| OMIM | Genetics | OMIM (Online Mendelian Inheritance in Man) is a comprehensive, online database that catalogs human genes and genetic disorders. It contains information on all known mendelian disorders and over 16,000 genes. | Link |
| JASPAR | Genetics | JASPAR is a database of curated, non-redundant transcription factor (TF) binding profiles stored as position frequency matrices (PFMs) and TF flexible models (TFFMs) for TFs across multiple species in six taxonomic groups. | Link |
| ClinVar | Genetics | ClinVar is a public database that aggregates information about the clinical significance of genetic variants. | Link |
| OpenTargets | Genetics | OpenTargets is a platform that use human genetics and genomics data for systematic drug target identification and prioritisation. It combines information from multiple sources, including genomics, transcriptomics, proteomics, and clinical data, to evaluate the relationship between genes, diseases, and potential therapeutic interventions. | Link |
| dbSNP | Genetics | dbSNP (Database of Single Nucleotide Polymorphisms) contains human single nucleotide variations, microsatellites, and small-scale insertions and deletions along with publication, population frequency, molecular consequence, and genomic and RefSeq mapping information for both common variations and clinical mutations. | Link |
| Monarch | Interaction | Monarch is a knowledge platform focused on integrating and analyzing data related to genotype-phenotype relationships across various species, including humans. | Link |
| AlphaMissense | Interaction | AlphaMissense is an adaptation of AlphaFold fine-tuned on human and primate variant population frequency databases to predict missense variant pathogenicity. | Link |
| BioGRID | Interaction | BioGRID (Biological General Repository for Interaction Datasets) is an public database that collects and curates data on protein and genetic interactions across various organisms. | Link |
| IntAct | Interaction | IntAct is a public database managed by the European Bioinformatics Institute (EBI) and provides information on molecular interactions, primarily focusing on protein-protein interactions and supporting a wide range of interaction types, including direct physical interactions and indirect associations. | Link |
| STRING | Interaction | STRING (Search Tool for the Retrieval of Interacting Genes/Proteins) is a comprehensive database and web resource that provides information on known and predicted protein-protein interactions. It integrates data from various sources, including experimental studies, computational predictions, and literature, to offer a detailed view of protein interactions within biological systems. | Link |
| Complex Portal | Interaction | Complex Portal is a manually curated, encyclopaedic resource of macromolecular complexes from a number of key model organisms. The majority of complexes are made up of proteins but may also include nucleic acids or small molecules. | Link |
| PDBe Chem | Ligands | PDBe Chem provides chemical and structural information about small molecules within the structure entries of the Protein Data Bank. Tools are provided to search the PDB dictionary for chemical components. | Link |
| Reactome-Chebi | Pathway | Chebi to reactome mapping | Link |
| Reactome | Pathway | Reactome database provides information about biological pathways and processes. It offers curated data on the interactions and reactions involving proteins, genes, and small molecules within various cellular pathways. | Link |
| GSEA - MSigDB | Pathway | MSigDB (Molecular Signatures Database) is a curated collection of gene sets that represent various biological states or processes, such as signaling pathways, gene ontologies, and gene expression signatures. These gene sets are used as input for GSEA to explore and interpret large-scale gene expression data. | Link |
| Geneontology | Pathway | Gene Ontology (GO) is a framework for classifying and describing the functions of genes across different species. It provides a standardized vocabulary for annotating genes in terms of biological process, molecular function, and cellular component. | Link |
| Scannet | Protein | Scannet provides information about the likelihood or confidence that a specific amino acid residue within a protein is involved in a protein-protein interaction (PPI). | Link |
| SWISS-MODEL | Protein | The SWISS-MODEL Repository is a database of annotated 3D protein models generated by automated homology modelling for relevant model organisms and experimental structure information for all sequences in UniProtKB. | Link |
| PDBbind-CN | Protein | PDBbind is a comprehensive collection of experimentally measured binding affinity data for all biomolecular complexes deposited in the Protein Data Bank (PDB). It provides an essential linkage between the energetic and structural information of those complexes. | Link |
| Protein Half Life (Paper) | Protein | data from paper: ‘Proteome-wide mapping of short-lived proteins in human cells’ | Link |
| Uniprot - Trembl | Protein | UniProt (Universal Protein Resource) is a comprehensive and highly curated database of protein sequence, functional annotations and protein variants information. It serves as a central repository for protein data. | Link |
| Compartments | Protein | Compartments is a database that provides detailed information about the subcellular localization of proteins (e.g., nucleus, cytoplasm, mitochondria). It integrates data from various sources, including experimental data, predictions, and high-throughput studies. | Link |
| SIFTS | Protein | Structure Integration with Function, Taxonomy and Sequence (SIFTS) is a project in the PDBe-KB resource for residue-level mapping between UniProt and PDB entries. SIFTS also provides annotation from the IntEnz, GO, InterPro, Pfam, CATH, SCOP, PubMed, Ensembl and Homologene resources. | Link |
| Uniprot - Swiss-Prot | Protein | UniProt (Universal Protein Resource) is a comprehensive and highly curated database of protein sequence, functional annotations and protein variants information. It serves as a central repository for protein data. | Link |
| Expasy - ENZYME | Protein | ENZYME is a repository of information relative to the nomenclature of enzymes. It is primarily based on the recommendations of the Nomenclature Committee of the International Union of Biochemistry and Molecular Biology (IUBMB) and it describes each type of characterized enzyme for which an EC (Enzyme Commission) number has been provided. | Link |
| InterPro | Protein | InterPro provides functional analysis of proteins by classifying them into families and predicting domains and important sites. InterPro uses predictive models, known as signatures, provided by several databases. | Link |
| Uniprot - Subcellular location | Protein | Uniprot - Subcellular location subsection provides information on the location and the topology of the mature protein in the cell. | Link |
| CHESS Isoforms | Protein Structure | The Comprehensive Human Expressed SequenceS (CHESS) database is a catalogue of genes derived from GTEx. In a follow up study the authors used AlphaFold to predict non-canonical isoform structures. | Link |
| SAbDab | Protein/Antibody | SAbDab database containing all the antibody structures available in the PDB, annotated and presented in a consistent fashion. | Link |
| Human Phenotype Ontology (HPO) | Terminology | The Human Phenotype Ontology (HPO) is a widely used resource that comprehensively organizes and defines the phenotypic features of human disease, enabling computational inference and supporting genomic and phenotypic analyses through semantic similarity and machine learning algorithms. | Link |
| NCBI Taxonomy | Terminology | The NCBI Taxonomy Database is a curated classification and nomenclature for all of the organisms in the public sequence databases. This currently represents about 10% of the described species of life on the planet. | Link |
| Orphanet/ORDO | Terminology | Orphanet provides a comprehensive resource for rare diseases including nosology, gene-disease relationships, external connections and an ontology (ORDO). | Link |
| EFO | Terminology | The Experimental Factor Ontology (EFO) provides a systematic description of many experimental variables available in EBI databases, and for projects such as the GWAS catalog. | Link |
| NCI Thesaurus | Terminology | The NCI Thesaurus (NCIt) is a comprehensive biomedical terminology that provides a structured vocabulary for cancer research and clinical care. | Link |
| Oncotree | Terminology | OncoTree is a comprehensive, community-led cancer classification system that adapts to the evolving demands of precision oncology. | Link |
| Cell Ontology | Terminology | Cell Ontology provides a standardized vocabulary for describing cell types and their relationships across different biological contexts. | Link |
| MeSH | Terminology | Medical Subject Headings (MeSH) is a comprehensive vocabulary used for indexing, cataloging, and searching biomedical and health-related information including terms for diseases, chemicals, drugs, procedures, and other health-related concepts | Link |
| Mondo | Terminology | The Mondo Disease Ontology (Mondo) aims to harmonize disease definitions across the world. it standardizes the classification and naming of diseases across different medical and biological databases. | Link |
| Disease Ontology | Terminology | The Disease Ontology has been developed as a standardized ontology for human disease with the purpose of providing the biomedical community with consistent, reusable and sustainable descriptions of human disease terms, phenotype characteristics and related medical vocabulary disease concepts | Link |
| UBERON | Terminology | Uberon is an anatomical ontology that represents body parts, organs and tissues in a variety of animal species, with a focus on vertebrates. | Link |
| Cellosaurus | Terminology | Cellosaurus is a knowledge resource on cell lines. It attempts to describe all cell lines used in biomedical research. It includes information such as their origin, characteristics and genetic information | Link |
| UMLS | Terminology | UMLS (Unified Medical Language System) is a comprehensive framework and set of resources developed by the U.S. National Library of Medicine (NLM) to facilitate the integration and interoperability of biomedical information. | Link |
| Mouse Genome Informatics (MGI) | Terminology | The Mouse Genome Informatics (MGI) database MGD serves as a primary resource for a spectrum of genetic, genomic and biological data supporting the use of the mouse as a model for understanding human biology and disease. | Link |